据韩国经济日报报道,SK海力士近日在IEEE(电气与电子工程师协会)全球半导体大会上发表论文,提出了一种全新的存储架构。据悉,该架构名为“H³(hybrid semiconductor structure)”,同时采用了HBM和HBF两种技术。
在SK海力士设计的仿真实验中,H³架构将HBM和HBF显存并置于GPU旁,由GPU负责计算。该公司将8个HBM3E和8个HBF置于英伟达Blackwell GPU旁,结果显示,与单独使用HBM相比,这种配置可以将每瓦性能提升高达2.69倍。
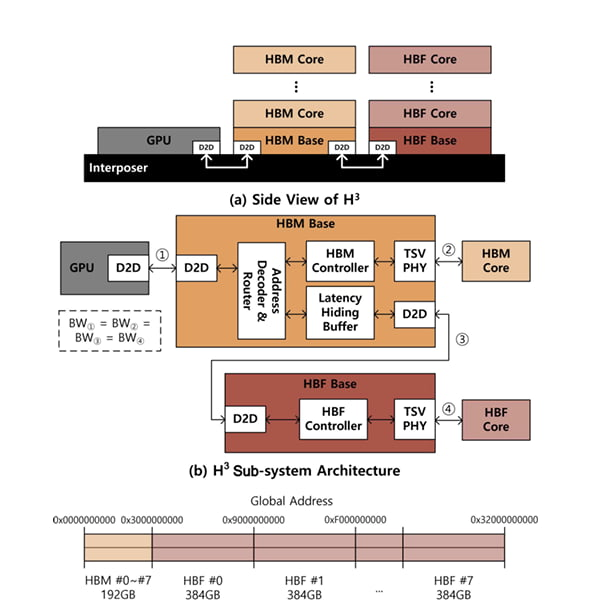
图源:SK海力士
实验结果显示,H³架构在AI推理领域尤其具有优势。推理的核心是键值缓存 (KV cache),它用于临时存储数据,以理解 AI 服务与用户之间交互的流程和“上下文”。然而,随着 AI 性能的提升,KV缓存容量不断增长,以至于HBM和GPU逐渐应接不暇。
因此,HBF被视作上述架构的核心。与堆叠DRAM芯片的HBM类似,HBF通过堆叠NAND闪存而制成。被称作“HBM之父”的韩国科学技术院(KAIST)教授金正浩类比道,HBM与HBF就好比书房与图书馆。前者容量虽小,但使用起来方便;后者容量更大,但也意味着延迟更高。
通过在HBF中存储KV缓存,GPU和HBM可以减轻存储KV缓存的负担,从而专注于它们在高速计算和创建新数据方面的优势。SK海力士模拟了HBF处理高达1000万个令牌的海量键值缓存的场景,结果表明,与仅使用HBM的配置相比,该系统处理并发查询的能力提升了高达18.8倍。以前需要32个GPU才能完成的工作负载,现在只需两个GPU即可完成。
该公司强调HBF在这篇论文中具有潜力。业界正在关注它是否能成为继目前SK海力士最大利润产品HBM之后的新AI存储器。
图源:SK海力士
然而,HBF要成为现实,必须解决各种问题。NAND闪存具有大的存储容量,但具有记录新数据或更改形式的写入性能慢的缺点。即使HBF只放置在读取混合结构数据的地方,写入性能对于KV缓存来说也越来越重要,因此需要设计技术来克服这一点。HBF底部基模的控制器性能必须比HBM先进得多。